
A scholarly publisher’s responsibilities can be split among the broad functions of registration, validation, dissemination, and archiving, with the validation of scientific work through peer review perhaps being the most central of all. For preprints, the responsibilities are similar with the exception of validation. Validation has historically been left to journals, while preprints have focused on rapid and early dissemination. Social media, COVID-19, and wider attention to science have boosted the disseminating power of preprints. Yet, dissemination makes validation imperative; without the latter, there is the risk of unvetted research getting into the public domain and, much worse, that of preprints being seen as weak or pseudo-science.
The preponderant view is that science builds on and corrects itself over time. However, that may come with a level of risk we are uncomfortable with. To build trust in science and in the role of preprints to disseminate trustworthy science, there is a need for some form of quality control in the preprint workflow.
Did someone say badges?
It is an unsaid truth that journal peer review works best when it is needed the least. Journal peer review is not set up to handle all the responsibility of vetting science. However, in conjunction with checks further upstream, peer reviewers could be freed up to focus on the crux of scholarly research. Quality checking on preprint servers is largely manual and involves resource-intensive processes. On preprint servers today, it is not atypical for manuscripts to go through a two-step process involving a basic check for completeness and additional checks specific to the domain. Pre-screening is the single biggest cost head for any preprint with consistent volumes, mostly consisting of staff time (i.e., reviewing, checking, and approving submissions). This cost will only go up as the need for faster and broader quality control deepens. Advanced text intelligence offers us certain benefits. A system of automated badges built on natural language processing and machine learning could provide a granular validation of research that is not binary but would publicly indicate research merit/rigor along a sliding scale.
BADGES COULD PROVIDE A GRANULAR VALIDATION OF RESEARCH THAT IS NOT BINARY BUT PUBLICLY INDICATES RESEARCH MERIT/RIGOR ALONG A SLIDING SCALE.
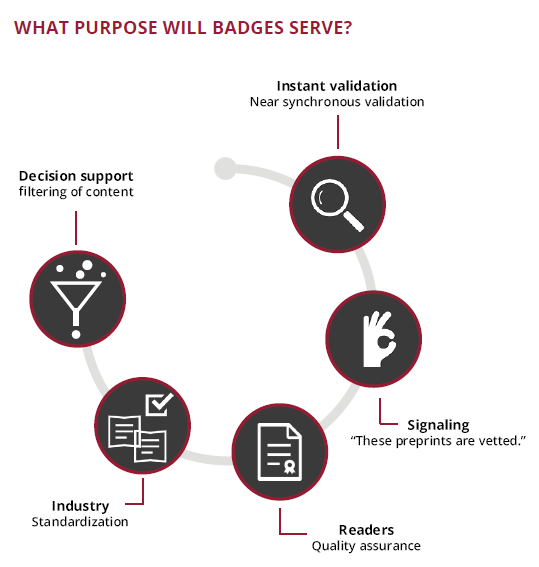
What purpose will badges serve?
By tagging preprints with various indicators, badges may represent quality, rigor, and scope. In doing so, they will ensure better forward linking of early research for various stakeholders. At the industry scale, badges on preprints have the potential to signal scientific merit along a range, not based on a one-size-fits-all metric like the Journal Impact Factor (JIF). Their benefit could trickle downstream to traditional publishing workflows too. If preprint badges could be ported to journal peer review, they may ease up the peer review burden and even facilitate the process of transferring reviews.
Preprints: From today to tomorrow
Several of the existing preprint services lack a scalable business model. They are often run by volunteer academic groups dependent on endowments from foundations and contributions from libraries. Offering value-added services
courtesy of badges could be a way to find preprints a reliable and systematic revenue source. Badges could be the quality standard unifying the different islands of scholarly publishing workflows. To this end, there is plausible reason to believe that publishers and funders could work actively with preprint servers to improve scholarly communication.
This piece is part of the Cactus whitepaper “Imagining the Post-COVID World of Scholarly Communication. Download the full whitepaper here.

Satyajit Rout
Satyajit Rout is Vice President, Strategy, at Cactus Communications.

Christopher Leonard
Chris is Director of Products & Strategy at CACTUS and has over 20 years’ experience in managing publishing workflows in editorial and product roles alike. He has developed preprint servers, overseen manuscript submission, and launched manuscript assessment services, besides being an ex-member of the COPE council.